ML 팀 프로젝트 마무리 후기
해당 글에서는 ML 팀 프로젝트 마무리 후기에 대해 소개합니다.

ML 팀 프로젝트 마무리 후기
프로젝트 소개
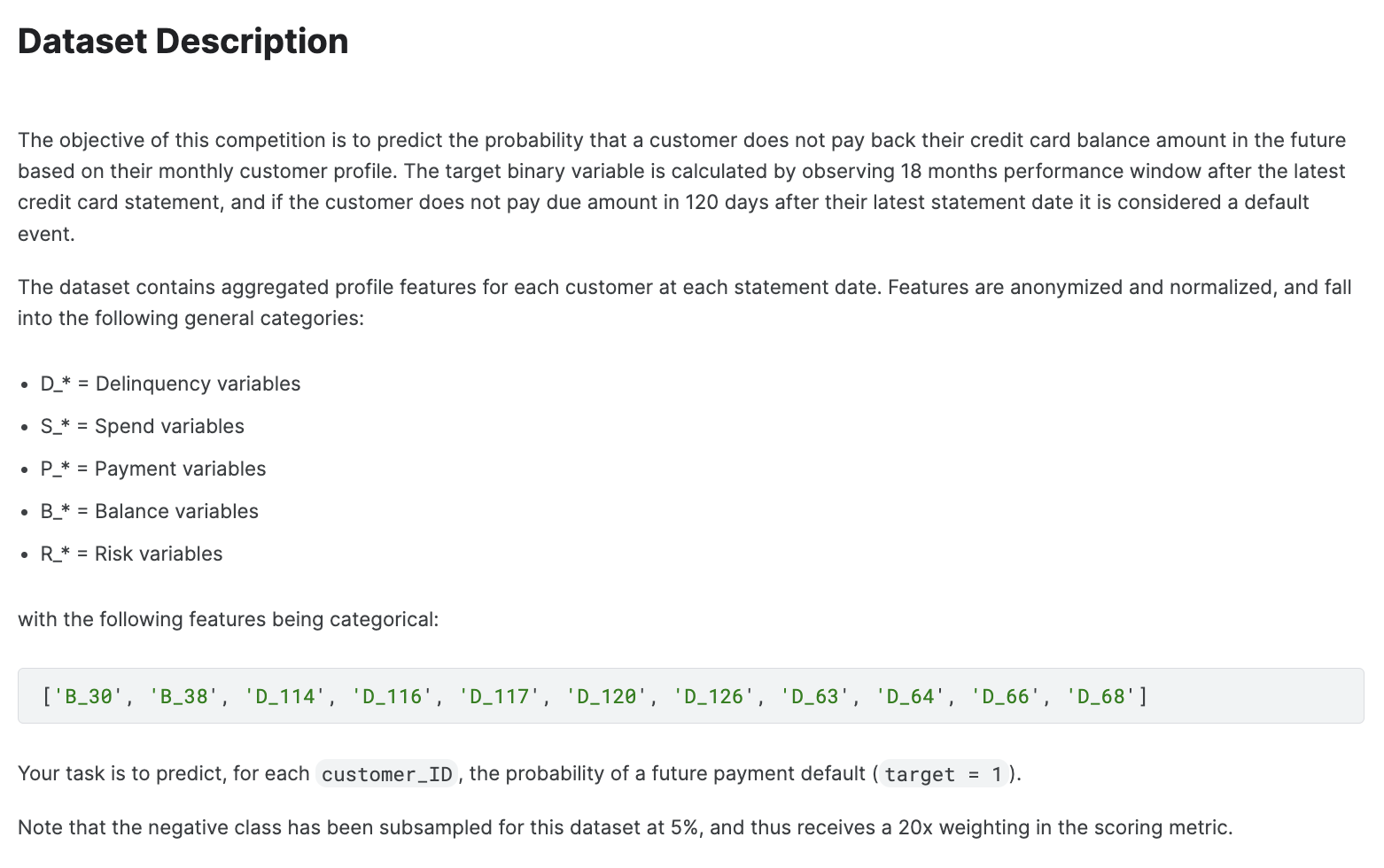
ML 팀 프로젝트는 약 2주간 진행되었으며 예전 Kaggle Competition에서 열렸던 American Express - Default Prediction 대회의 데이터를 활용하여 진행되었다. American Express에서 신용 불량자를 예측하는 대회로 구매, 연체율, 잔액, 신용 불량 위험지수 등의 컬럼값으로 구성 되어 있으며 AMEX Metric Score를 통해 평가가 이루어졌다.
대회 설명

American Express는 글로벌 통합 결제 회사이며 세계 최대의 결제 카드 발급사인 이 회사는 고객에게 삶을 풍요롭게 하고 비즈니스 성공을 구축하는 제품, 인사이트, 경험을 제공한다.
이번 대회에서는 머신러닝 기술을 활용하여 신용 불량을 예측하는 과제를 수행하게 됩니다. 특히, 산업 규모의 데이터 세트를 활용하여 현재 운영 중인 모델에 도전하는 머신러닝 모델을 구축해야 합니다. 훈련, 검증 및 테스트 데이터 세트에는 시계열 행동 데이터와 익명화된 고객 프로필 정보가 포함됩니다. 기능 생성부터 모델 내에서 보다 유기적인 방식으로 데이터를 사용하는 것까지, 가장 강력한 모델을 만들기 위한 모든 기술을 자유롭게 탐색할 수 있습니다.
AMEX Metric Score Code
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
def amex_metric(y_true: pd.DataFrame, y_pred: pd.DataFrame) -> float:
def top_four_percent_captured(y_true: pd.DataFrame, y_pred: pd.DataFrame) -> float:
df = (pd.concat([y_true, y_pred], axis='columns')
.sort_values('prediction', ascending=False))
df['weight'] = df['target'].apply(lambda x: 20 if x==0 else 1)
four_pct_cutoff = int(0.04 * df['weight'].sum())
df['weight_cumsum'] = df['weight'].cumsum()
df_cutoff = df.loc[df['weight_cumsum'] <= four_pct_cutoff]
return (df_cutoff['target'] == 1).sum() / (df['target'] == 1).sum()
def weighted_gini(y_true: pd.DataFrame, y_pred: pd.DataFrame) -> float:
df = (pd.concat([y_true, y_pred], axis='columns')
.sort_values('prediction', ascending=False))
df['weight'] = df['target'].apply(lambda x: 20 if x==0 else 1)
df['random'] = (df['weight'] / df['weight'].sum()).cumsum()
total_pos = (df['target'] * df['weight']).sum()
df['cum_pos_found'] = (df['target'] * df['weight']).cumsum()
df['lorentz'] = df['cum_pos_found'] / total_pos
df['gini'] = (df['lorentz'] - df['random']) * df['weight']
return df['gini'].sum()
def normalized_weighted_gini(y_true: pd.DataFrame, y_pred: pd.DataFrame) -> float:
y_true_pred = y_true.rename(columns={'target': 'prediction'})
return weighted_gini(y_true, y_pred) / weighted_gini(y_true, y_true_pred)
g = normalized_weighted_gini(y_true, y_pred)
d = top_four_percent_captured(y_true, y_pred)
return 0.5 * (g + d)
🗓️ 2024.06.03 ~ 2024.06.05 (1주차)
1주차에는 우선 데이터를 가지고 분석하고 Feature Engineering을 진행을 하였다. EDA에서 우선 어떤 컬럼들 끼리 상관관계가 있는지 알아보기 위해 Heatmap을 그려보았다. 또, 데이터의 결측치를 확인해보았다. 여기서 AMEX Dataset은 결측치가 99% 이상을 넘기는 컬럼들이 몇 개 있었기 때문에 이 부분을 주의 하면서 데이터를 분석하였다.
🗓️ 2024.06.10 ~ 2024.06.14 (2주차)
2주차에는 1주차에 분석한 데이터를 바탕으로
XGBoost 모델로 데이터 학습
- 2주차에는 모델을 구축하고, 모델을 평가하고, 최종 결과를 도출했습니다.
- 모델을 구축하면서 어떤 하이퍼파라미터를 사용할지, 어떤 모델을 사용할지 등을 논의했습니다.
CatBoost 모델로 데이터 학습
- 2주차에는 모델을 구축하고, 모델을 평가하고, 최종 결과를 도출했습니다.
- 모델을 구축하면서 어떤 하이퍼파라미터를 사용할지, 어떤 모델을 사용할지 등을 논의했습니다.
1
2
🌜 개인 공부 기록용 블로그입니다. 오류나 틀린 부분이 있을 경우
언제든지 댓글 혹은 메일로 지적해주시면 감사하겠습니다! 😄